Informations
Jobs
Rethinking semantic product search: a new approach to queries with unusual spelling variations
In recent years, semantic product search has been widely adopted in global e-commerce. However, many systems exhibit issues in understanding queries with unusual spelling variations. In this blogpost, we show you how Otto’s Team Turing has developed a new system that alleviates these problems. It is live and has lifted the Click-Through Rates (CTR) in the low-recall segments of otto.de by more than 25% and the Conversion Rate (CvR) in the low-hit segment by more than 90%.
You can also view a detailed presentation of this article at this year’s Otto’s MAIN-conference.
“Iphone” is a popular query on otto.de. However, due to uncertainties about the spelling, many customers enter different variations ranging from “aifonpromax13” to “eifon”. This poses a significant challenge for the search system on otto.de. Standard lexical search systems cannot deal well with queries with spelling errors. Therefore, Otto has entrusted a new team, Team Turing, with the development of a robust semantic search engine. In this blogpost, we showcase our new system.
Semantic search systems display products that match the sense, i.e. the semantics, of the query. Lexical systems, on the other side, match the similarity of the spelling of a query and relevant products. Due to the different approaches, semantic systems can be tuned better than lexical systems to deal with unusual spelling variations.
Image 1 shows how the results of our lexical and new semantic system are displayed on otto.de. If a customer enters a difficult query variation into the search box (green box), the lexical system cannot retrieve a result and displays an according message (lila box). The new semantic system, however, can retrieve relevant results and displays 18 products below the heading “Ähnliche Artikel” or “Kunden suchten auch” on the website (red box).
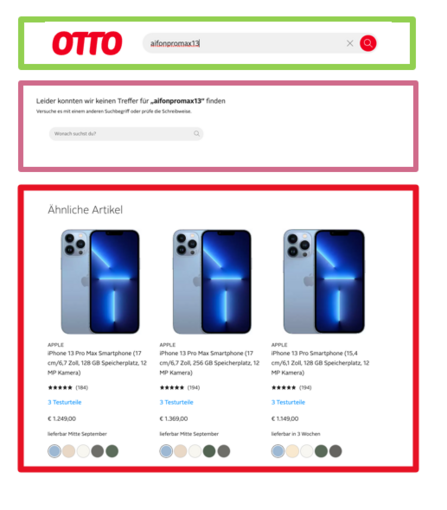
Image description: A zero-hit page on otto.de. While the lexical system cannot find any products (lila box) for the query “aifon13promax”, the new semantic retriever finds the correct results (red box).
Lexical systems have dominated the market for search systems for a long time. However, with the advance of Artificial Intelligence semantic product search have taken off in recent years. However, due to the relative newness of these systems, many aspects have so far not been fully explored. One of these issues, is the extent to which semantic systems can be tweaked to deal better with difficult queries with spelling mistakes. The new system that we are presenting falls into this research field and pushes the boundaries of it.
To understand the benefits of our new architecture, we first need to explain how semantic product search works. Semantic product search is based on query-product click-data. When a user enters a query “q1”, he or she defines the meaning, i.e., the semantics of the query term, by clicking on products such as “p1” or “p2”. We only know that the query “eiphone” means “iphone” when a user clicks on the relevant product. The main idea of distributional semantics as applied to this click-problem is that the meaning of a query is defined by the context of clicked products. This definition defines the semantics of the query independent of its spelling.
Once we have obtained the meaning of a query, we need to determine the relevant products for retrieval. For this we use a clustered bipartite graph that we build from the query-product click- data from the clickstream of our e-commerce store. The edges define positive clicks between a query and a product. The advantage of using such a product-query click-graph as the basis of a semantic search system is that one can cluster it and, thus, reveal all relevant products in relation to a query, even if they were not clicked directly in relation to it. (See image 2) From the query-product graph, one can infer that p3 is relevant to the query q1, for example. The retrieval of relevant products from adjacent clusters of relevant products for a given query is the basis of semantic product search.
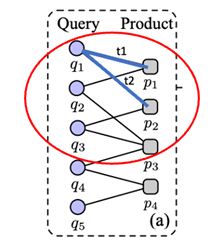
Image description: A bipartite query-product click graph. The red circle exhibits the cluster of relevant products. The cluster defines the relevance boundary for the retrieval of an additional product p3 in relation to q1 that is not directly linked. The links are aggregated over time. Different times are indicated by t1 and t2. Image partially based on graph in: Zhang et.al (2019): Neural IR meets Graph Embedding. In: WWW Conference 2019, pp. 2390-2400.
However, a semantic query-product click-graph has a drawback. It is solely based on historical click-data and cannot be generalized to unseen queries for which such data do not exist yet. In order to generalize a click-graph, it can be projected into a semantic dense vector space. This projection is done by embedding textual representations of the query- and product-nodes into the vector space and by aligning the semantics of the vector space to the structure of the query-product click-graph. More precisely, edges of the graph in the form of “query text”-“product title” are embedded and their click-distances are learned. Based on this secondary semantic, known queries and products can be generalized. In other words, the system can be trained to understand newly entered query-texts and to infer relevant products for such an unknown query.
However, by using the textual representations of queries more explicitly, the system becomes prone to spelling errors. Language models that underpin dense semantic vector spaces are learning the semantics of a word based on tokens of this words. They split the word “iphone”, for example, into “I” and “phone. However, if they encounter a spelling mistake inside a known longer token such as “phone”, they often fail to infer the meaning of the full word. One can demonstrate these problems with relation to our not optimized test-system. After a customer has entered “shower faucet” with a spelling mistake, the system retrieves dog costumes.

Image description: Generalisation problem of a previous-generation semantic search system in the low-recall segments: the system is confused by spelling mistakes of queries.
In order to fix this problem, one needs to change the language model in a fundamental manner towards a stronger query-centricity. Traditionally, language models that underpin semantic product search have often been trained with product- and query-texts. However, since product-texts are usually much longer, this often does not leave not enough bandwidth in these models to learn all kind of different query variations.
We have alleviated this problem by training the model on queries only and have included all query texts with spelling mistakes. In addition, we have fundamentally altered the tokenization strategy and have used more and smaller tokens for the training of the language model so that it can learn the correct semantic despite variations in the spelling. This makes the model much more robust.

Image description: The solution architecture consists of three modules and an additional ranking system.
The main task of the aggregator is to collect click-data from the clickstream. In this module, we collect wrong-spelled queries and link them to clicked products per session. In this way, we can learn the meaning of misspelled queries through the clicked products in the context.
The second module in the pipeline is a query-understanding component. In this component, we map unseen queries to known queries. In addition, we have added a k-nearest neighbour search component to the module. For each incoming query, we look up the k-nearest neighbouring known queries in a dense vector space.
Finally, we use the retrieved k similar queries to find relevant products which are stored in a graph-based look-up table. We note that well-formed clusters of products and queries in the query-product click-graph are often exhibiting a high degree of textually semantically similar queries. Thus, we use the k similar queries to collect products in clusters from a query-product click. This constitutes a new and effective method for aggregating clusters, even fragmented ones, in a sparse click-graph with query spelling variations. As shown in image 1 above, our system can retrieve the correct iphone models after a user enters the query “aifon13promax”.
We have then incorporated the language model into a pipeline architecture for semantic search. For the solution architecture, we have divided our system into three modules: an aggregator, a denoising query understanding module with the new language model and a semantic retriever.
After the development, we have deployed the new system to the webshop otto.de for a live A/B test. The result was that our new model has been able to lift the conversion Rate in the 0-hit segment by 25% and in the low-hit segment by more than 90%. We are very pleased with this outcome which has underlined the fruitfulness of our problem analysis and our new robust query-centric solution approach.
Want to be part of our team?



We have received your feedback.


